RPC调用过程
RPC调用过程
RPC五大核心组成
- server(provider) :服务提供者
- server-stub(provider-stub) :服务端的本地存根。进行类型和参数转换,“翻译员”
- user(consumer):服务消费者
- user-stub(consumer-stub) :消费端的本地存根
- RPCRuntime:RPC通信者。负责传输数据包,服务端/消费端均存在一个RPCRuntime,负责两边的通信
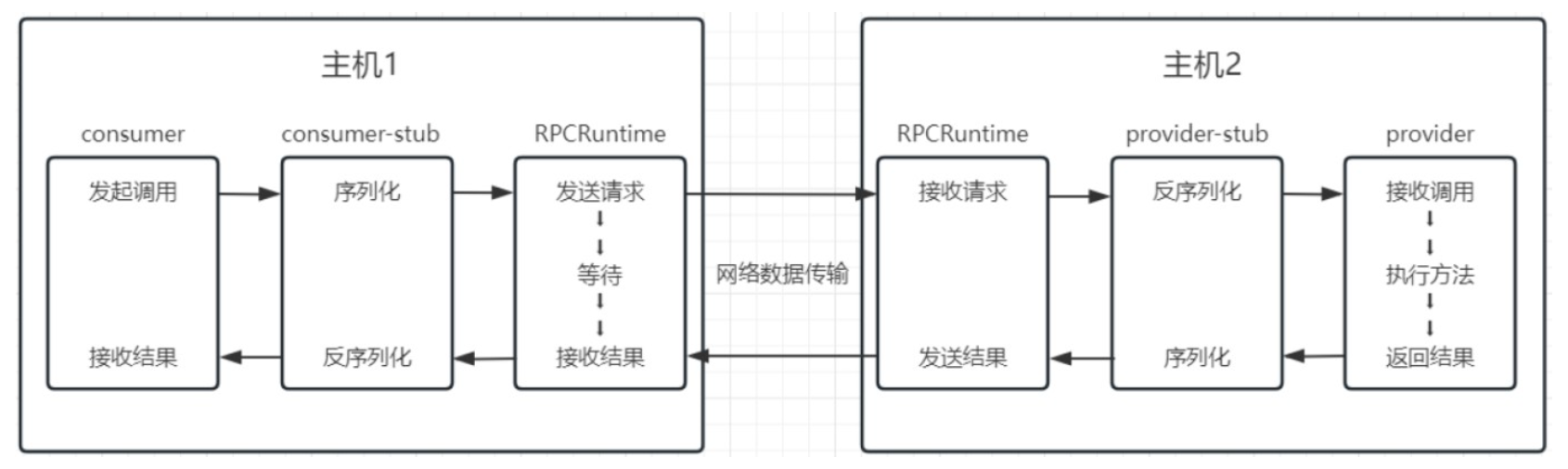
完整的RPC中隐藏了许多细节,比方服务发现、序列化等等。RPC框架则能屏蔽这些细节,让使用者无感地调用RPC
RPC框架的主要问题
- 服务发现:各服务如何互知对方地址(注册中心)
- 通讯协议:调用方和服务方如何通信(TCP/HTTP)
- 序列化:通信消息如何解压缩(文本型Json/XML;二进制型)
- 代理:调用方如何像调用本地API一样无感调用RPC
服务发现
服务可以通过固定的IP或者DNS域名解析来发现其他服务的地址,但这些除扩展性差外,对服务上下线状态也不敏感
注册中心的服务注册表可以记录各个微服务实例的信息,服务启动时主动将信息注册到服务中心,用于调用方查询,同时提供服务检查,如果心跳探测不到实例则会将服务移出注册表
注意,注册中心只提供服务发现功能,并不转发客户端的调用请求
通讯协议
gRPC采用HTTP2协议,Dubbo采用TCP协议。
传输数据格式有文本格式如JSON、XML;也有二进制格式如JDK原生序列化。二进制方式数据包小,传输速率块,但对于异构型语言并不友好,主要因为二进制不好被反编码到其他语言。
(NOTE) 异构型语言解决方案
- 规定各语言以相同的机制序列化,如Hession、Json
- 采用IDL作为标准描述语言,如Thrift、ProtoBuf
路由
- 测试场景下,客户端的测试实例需要路由到特定服务实例上
- 流量隔离场景下,将流量隔离到不同服务实例上
- 灰度发布时,新服务只会接受少量的请求
- 路由规则由注册中心下发给客户端
负载均衡算法
轮询算法:按照服务节点列表的顺序轮流发送请求
随机算法:随机选取服务节点中的一个服务节点发送请求
加权随机算法:按权重随机服务节点,权重大的被选中概率更大
最少活跃数算法:对每个服务节点设置活跃数,每发送一个请求活跃数加1,每完成一个请求活跃数减1,服务运行一段时间后,性能相对较高的节点处理请求更快,活跃数下降得快,因此消费者只需要选择活跃数最小的节点发送请求
一致性hash算法:使用hash计算,尽可能将请求均匀分配到后端服务,并且同一个用户的请求总
是访问到同一个服务器
熔断机制
服务实例在一段时间内出现故障导致响应过慢或者出现错误过多,实例就会被熔断
服务中某个实例被熔断后,调用者的请求会被转发给剩余正常的实例
优雅启动和优雅宕机
在微服务架构中,服务的频繁上下线,系统的扩缩容都是常见现象,这些现象发生时应当对整个系统是无损的
优雅启动
新服务完全启动后,通过Hook自动将信息发布到注册中心。新服务还不能承担全体流量。应随着时间的增加逐渐提升自身权重,最后与旧服务持平。
优雅宕机
宕机时先在注册中心注销,不被客户端发现。随后处理完已接受的请求,再关闭服务。期间如果有新请求则返回错误码,让客户端转发到其他客户端重试
gRPC
HTTP2
HTTP/1.x的性能存在问题,主要因为同一连接同一时间只能处理一个请求,其他请求的多数时间浪费在了阻塞等待上。
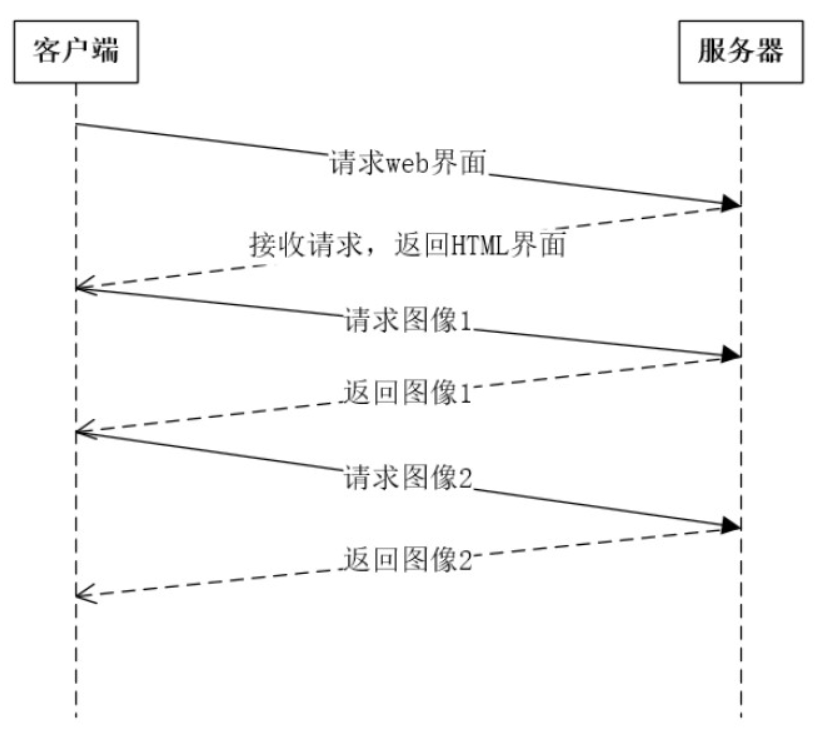
HTTP/1.1管道化解决了请求的阻塞问题,但队头阻塞依然存在,且返回也要按照请求顺序,否则会被阻塞。
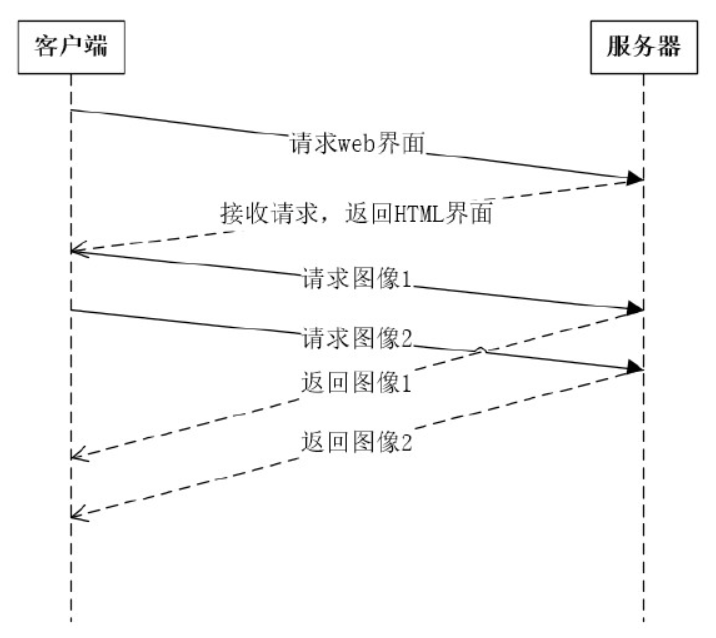
HTTP/2以流的方式分组,能够多路复用同一个TCP连接。

protobuf
protobuf支持多语言,在使用前通过预先定义的Schema来下序列化各种语言代码,保证传输出去的数据包格式一致。
protobuf工作时,先将.proto“一式两分”地转为客户端存根供客户端调用,另一个作为服务基类嵌入服务器中。此后,客户端直接调用存根即可调用启用服务,就像是调用本地API一样。
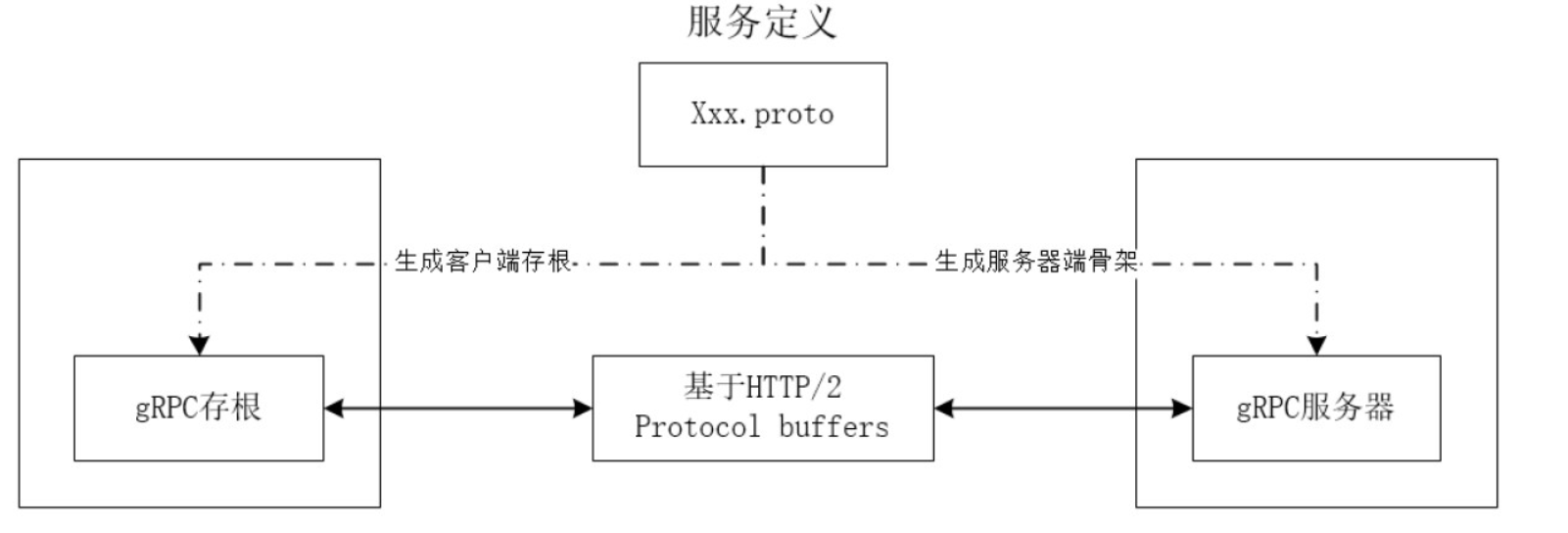
RPC模式
- 一元RPC:一次请求对应一次响应
- 服务端流模式:一次请求,服务器返回连续的数据流
- 客户端流模式:客户端源源不断发送数据流,而在发送结束后,服务端返回一个响应
- 双向流模式:客户端与服务端都可以向对方发送数据,实现实时交互
gRPC缺点
不提供服务发现、负载均衡
protobuf可读性差
不支持动态Schema
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!