Redis简言
Redis简言
底层数据结构
graph TD
A(String) --> B[简单动态字符串:embstr/raw]
A --> b[int]
C(List) --> D[双向链表]
C --> E[压缩列表]
F(Hash) --> E
F --> G[哈希表]
H(Sorted Set) --> E
H --> I[跳表]
J(Set) --> G
J --> K[整数数组]
RedisObject
redisObject定义在redis.h中,用于表示所有类型的key,value。其中有一些重要属性
- type:表示数据类型,包括String、List、Hash、ZSet、Set
- encoding:表示数据的编码方式,即双向链表,压缩列表,动态字符串等等
- ptr:数据指针,指向数据的真实存储位置
String
String有三种编码方式:int、raw、embstr。
当value为整型时,encoding设为int,ptr指向数字的储存位置。
当value为字符串,且字符串长度不多于32字节时,encoding设为embstr,否则设为raw。ptr则都指向SDS(simple dynamic string)结构。
SDS结构包含三个属性:buf[]为字符组,free表示buf还未利用的空间大小,len表示字符串长度
Hash
哈希表
Hash的底层储存结构主要是字典dict,该结构包含两个重要属性:ht,rehashidx标志渐进式rehash的进度。其中ht由两个dictht类型数组构成,其中一个是数据的储存位置,一个用于rehash。
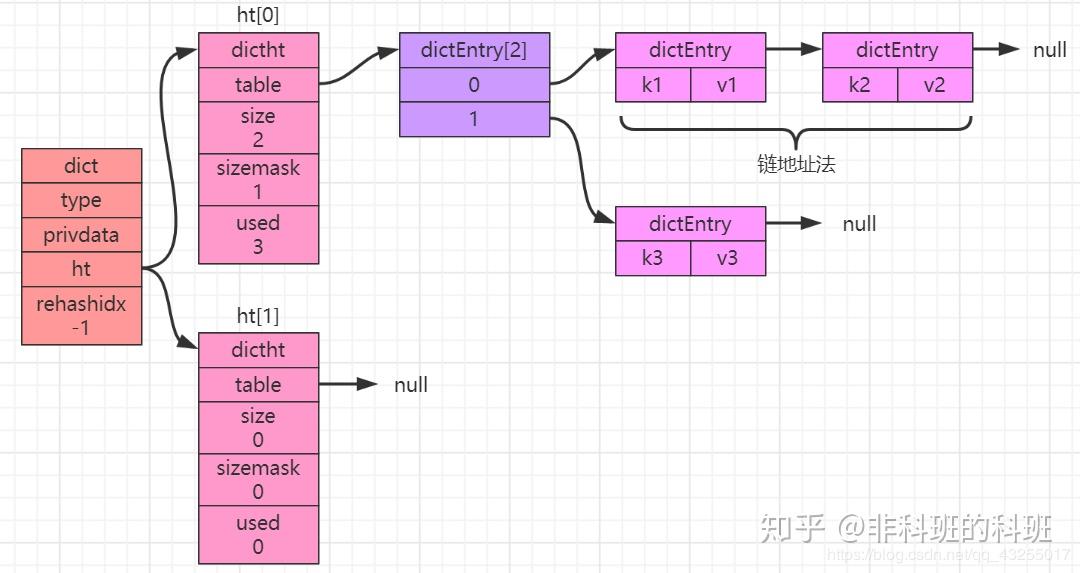
dictht结构的几个重要属性:table:储存键值对dictEntry的数组,size:数组table的长度,sizemask:等于size-1,用于hash寻址,used:表示已有的dictEntry数量
dictEntry结构的几个重要属性:key为HKey,v为HValue,next指向下一dictEntry
渐进式rehash
redis通过链地址法解决Hash冲突,但冲突率过高就需要进行扩容,要扩容就要对所有节点rehash。可以试想,如果在一个dictht上rehash,该dictht在rehash过程中是不可用的。这也就是为什么会有第二个dictht,在第一个dictht的节点rehash到第二个dictht的过程中,redis依然是可以对外提供服务的,这也就是渐进式rehash。而rehashidx就是用来指示当前rehash到了哪个下标。
扩容时,ht[1].size会设定为N(2*ht[0].size <= N <= 2^n^,n尽可能取最小值),扩容过程中遍历所有节点并逐渐迁移到ht[1].table中
压缩列表
压缩列表是一段完整连续的内存块

zlbytes:4个字节的大小,记录压缩列表占用内存的字节数。zltail:4个字节大小,记录表尾节点距离起始地址的偏移量,用于快速定位到尾节点的地址。zllen:2个字节的大小,记录压缩列表中的节点数。entry:表示列表中的每一个节点。previous_entry_ength表示前一个节点entry的长度,可用于计算前一个节点的其实地址,因为他们的地址是连续的。encoding:这里保存的是content的内容类型和长度。content:content保存的是每一个节点的内容。
zlend:表示压缩列表的特殊结束符号'0xFF'
List
List底层除了使用压缩列表实现,也可以通过双向链表实现。
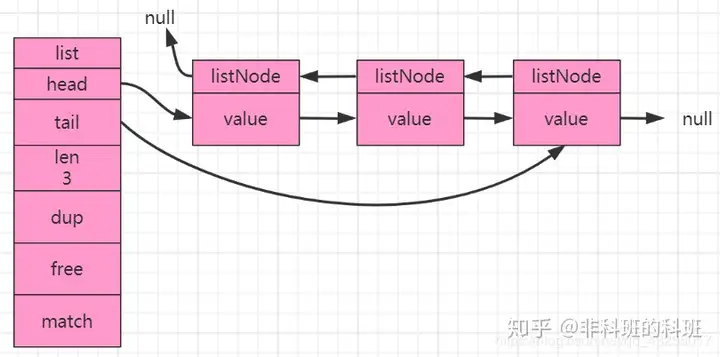
因为List双向链表的pop/push特性,所以List可用作是实现阻塞队列
Set
Set可以通过哈希表实现,区别于Hash,Set只是不解决哈希冲突问题。此外当集合的元素数量不多时,Set会通过整数数组实现

其中三个属性值encoding、length、contents[],分别表示编码方式、整数集合的长度、以及元素内容
Zset
当Zset中节点数量过多或节点过大时,Zset底部会由压缩表转换为跳表。
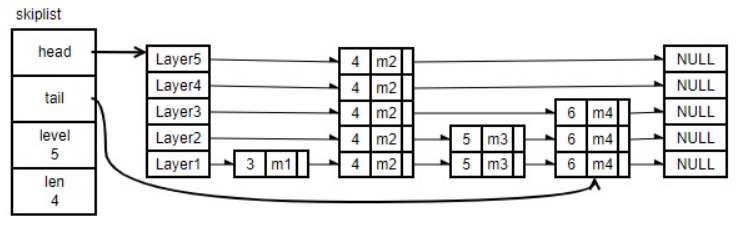
skipList本质是多层链表,只是每个高层节点都有一个指向正下方底层节点的指针。
插入节点时,会随机选取一个层级LayerN(从第1层到第32层的概率逐级递减,选取第一层有50%的概率)。该节点顺序插入到LayerN的链表中后,又会复制一份插入到LayerN-1的链表中,如此操作直到Lyaer1的链表也有该节点。
据此,我们可以知道跳表的一些基本特性:
- 跳表的最底层拥有所有节点
- 节点插入跳表后,从选取的层级开始,直到最底层都有该节点的副本。且上层节点有个指向下层节点的指针。
- 每层的链表是一个双向链表
查询score=5.5的节点
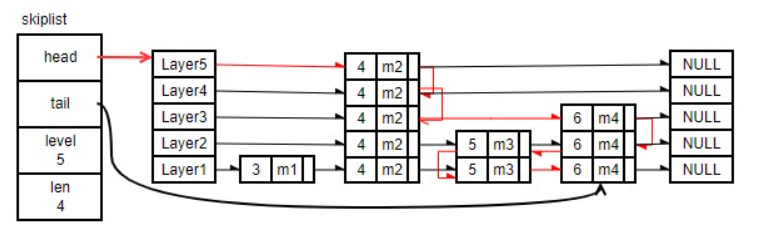
最后在底层的5和6之间发现5.5不存在。
集群
全量复制
当从节点首次加入集群或发生主从切换时,触发全量复制:
sequenceDiagram
从节点 ->>主节点: psync ? -1
主节点 ->>从节点: FULLRESYNC offset
Note right of 主节点: bgsave生成RDB
主节点 ->>从节点: 发送RDB
Note right of 主节点: 继续接受命令并写入bufferB
Note left of 从节点: 加载RDB
主节点 ->>从节点: 发送buffer
Note left of 从节点: 加载buffer
增量复制
当主从断开重连或主节点同步时,触发增量复制
sequenceDiagram
从节点 ->>主节点: 重连
从节点 ->>主节点: psync ID offset
主节点 ->>从节点: 从offset到最新数据的差值
Note right of 主节点: 继续接受命令并写入buffer
主节点 ->>从节点: 发送buffer
Note left of 从节点: 加载buffer
Sharding
Redis通过Hash分片将请求均匀地打到各个节点上,Hash = CRC16(Key)%2^14^。
重定向
当集群扩缩容后,各节点的位置都有可能有变化。这样客户端的请求就可能无法打到正确节点上,因此Redis节点在接受命令后先校验自身是否为目标节点,如果不是,则返回moved命令,指导客户端重定向到正确节点上。
哨兵分布式投票
Redis持久化
RDB
手动触发
save会阻塞当前Redis服务器,直到RDB生成。bgsave则是fork一个子进程来生成RDB文件,只有在fork的过程中会阻塞Redis服务器一段时间。
自动触发
- save m n:m秒中发生n次修改,自动触发bgsave
- 全量同步时触发bgsave
- 执行shutdown时,如果没有开启AOF则会触发bgsave
bgsave
bgsave执行的是cow(copy and write)流程,表面意义就是Redis将所有数据生成一份快照,子进程根据快照生成RDB,主进程则继续对外服务。但显然,Redis不会这么做,因为这会直接将可用内存削减掉一半。
Redis创建子进程后,不会进行copy,主进程和子进程共享数据。但是主进程会将所有内存页权限设置为read-only,当主进程尝试修改某一内存页时,会触发页异常中断。之后该页生成一份快照供子进程使用,解除限制的内存页就继续对外服务。这样,在理想状态下,如果主进程没有写操作,整个bgsave都不会产生额外内存开销。
AOF
写操作命令会追加到aof_buf缓冲区中,之后根据appendfsync策略决定何时将缓冲区写到AOF中
可以预想到,如果不做控制,AOF的体积会不断膨大。为此,Redis可以通过AOF重写将AOF中的命令压缩,以做到命令更少,但结果一致。
混合持久化
在aof文件重写时,fork一个子进程将内存数据以RDB二进制格式写入AOF头部,重写后执行的redis命令,会以aof持久化的方式追加到aof文件尾部。
Redis事务
Redis事务本质是将一组命令顺序排列,保证一次性执行完命令组。MULTI开启事务,EXEC结束事务并执行命令组。Redis事务相比于MySQL事务,不会进行回滚。
Redis不支持分布式事务,即事务中的所有命令都必须在同一节点上执行,否则事务丢失。Redis提供了Hash Tag作为Sharding Key,以保证带有同一Hash Tag的命令都会被分到同一slot中,如set {tag}key value
Redis并非完全不支持事务回滚,在事务开启前执行WATCH Key,如果事务过程中Key被修改,则回滚所有操作。
缓存设计
缓存一致性
为尽量保证缓存与数据库的数据是一致的,业内多采用延迟双删。修改数据库前删除缓存,修改成功后再次尝试删除缓存。
TTL设计
缓存最好都设置过期时间,以免冷数据长期占用内存空间。TTL过小会影响缓存命中率,TTL过大则会不必要地占用内存。如何在命中率和内存占用中权衡,有下经验:
递增式设置不同TTL,统计TTL内请求的用户量,请求总量。通过公式 $$ 命中率 = 1- \frac{TTL内请求的用户量}{TTL内请求总量}$$ 计算命中率,随后设计缓存类型是String还是Hash,在Redis内存估计中预算出TTL内缓存的内存占用量,其中Key个数约等于TTL内请求的用户量。
| 时间 | 10s | 30s | 1min | 10min | 20min | 30min |
|---|---|---|---|---|---|---|
| 设备数量 | 31296 | 35139 | 35261 | 37013 | 38523 | 38505 |
| 请求总数 | 31378 | 93770 | 187632 | 1878392 | 3755227 | 5631076 |
| 命中率(%) | 0.26 | 62.5 | 81.21 | 98.03 | 98.97 | 99.32 |
| 内存估计(M) | 5.16 | 5.79 | 5.81 | 6.10 | 6.35 | 6.35 |
列出数据后,比对可发现合适的TTL。
但注意,需要一些额外设计:
- 所有缓存设置同一TTL会引发缓存雪崩,为避免这一现象,应该在TTL基础上随机加盐。以上表为例,TTL设定在10min±3min比较合适
- 对于数据库中不存在的数据,应该在缓存中回写空值,以避免缓存穿透。对于不合理的请求,比如主键为负值,缓存就应该直接拒绝,以避免缓存穿透(布隆过滤器实现)
- 对于写多读少的场景,Redis持久化可以选择AOF或混合持久化;否则,RDB会更为合适
布隆过滤器
布隆过滤器由n个无偏Hash函数和二进制数组组成。某一Key在添加到过滤器的时候,会先通过n个无偏Hash函数获得n个hash值,这n个值落在二进制数组上就将该值改为1。如果需要查询某Key原先是否已存在,只需将该Key在二进制数组落点上的所有值进行与运算,结果为0则表示该Key不存在,但结果为1并不意味着一定存在,因为那些为1的落点有可能是其他Key落下的。
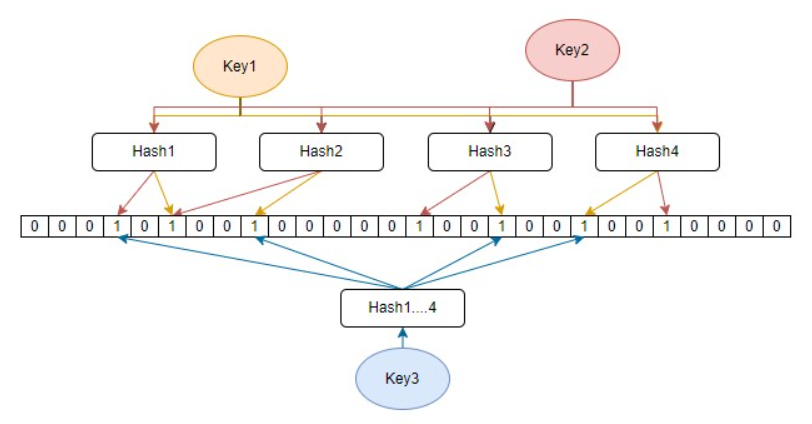
二进制数组越长,Hash函数越多就越容易减小Key3这种情况的概率。但这也会带来性能损耗,如何权衡便是一个问题,Bloom Filter Calculator能帮忙计算合适的数组长度和Hash数量。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!